




Разработка парсеров для 1С-Битрикс: с чего начать?
XMLReader, а не SimpleXML — выбор инструмента определяет судьбу проекта. SimpleXML загружает весь XML в память, и при файле поставщика на 800 МБ PHP упадёт с fatal error на лимите 512 МБ. XMLReader обрабатывает потоково, node за node, потребляя 20–30 МБ — в 30 раз эффективнее. С этой детали стартует любая разработка парсеров под Битрикс. Мы делаем такие системы уже 10+ лет, и ни один проект не обходится без правильного выбора парсера.
Какие проблемы решает парсинг?
- Первичное наполнение каталога — 15 000 карточек с описаниями, характеристиками, фото. Вручную это три месяца контент-менеджера; парсер — неделя с отладкой.
- Мониторинг цен конкурентов — сбор данных с Ozon, Wildberries, сайтов конкурентов. Конкурент снизил цену на ходовую позицию — узнаёте через два часа, а не через две недели.
- Агрегация поставщиков — пять прайсов в разных форматах (CSV с CP1251, XML в CommerceML, Excel с объединёнными ячейками) превращаются в единый каталог с общей системой свойств инфоблока.
- Обогащение карточек — подтягиваем характеристики, инструкции, 3D-модели с сайтов производителей. Без этого карточка товара — пустышка для SEO.
- Обновление ассортимента — товары, пропавшие из фида поставщика, деактивируются через
CIBlockElement::Update($ID, ['ACTIVE' => 'N']). Новые — создаются. Каталог синхронизирован.
Какие инструменты используем в разработке парсеров?
Статические сайты — PHP (Goutte, Symfony DomCrawler) или Python (Scrapy, lxml). Скорость: 50–100 страниц/сек. Хватает для каталогов без JS-рендеринга.
SPA и динамические сайты — Puppeteer или Playwright. Бесконечный скролл, AJAX-фильтры, lazy-load картинок — headless-браузер всё это обработает. Скорость падает до 1–10 страниц/сек, но альтернативы нет: данные существуют только после выполнения JavaScript.
Файлы поставщиков:
- Excel (XLS, XLSX) — PhpSpreadsheet. Осторожно с объединёнными ячейками и формулами — они ломают автоматический маппинг.
- CSV —
fgetcsv()с правильной кодировкой. Поставщики любят CP1251, BOM в UTF-8 и точку с запятой вместо запятой. Всё это нужно детектить и обрабатывать. - XML/YML — XMLReader для больших файлов, SimpleXML для фидов до 50 МБ.
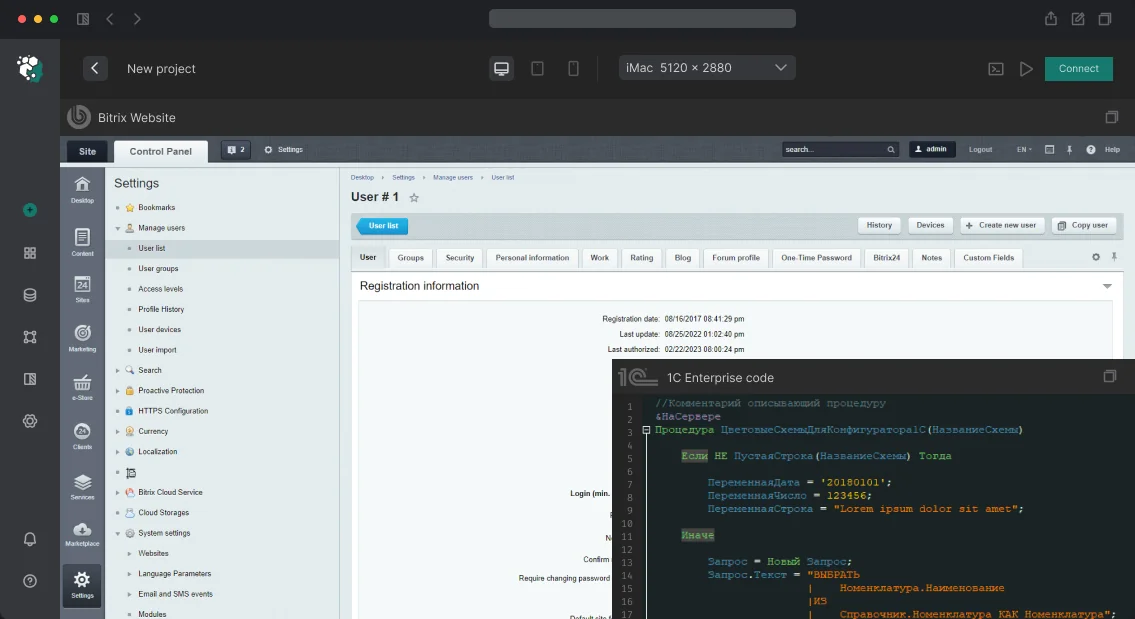
- CommerceML — стандартный формат обмена с 1С. Разбираем
import.xmlиoffers.xml, маппим на структуру инфоблоков.
API — REST-эндпоинты поставщиков, API маркетплейсов (Ozon Seller API, Wildberries API). Работаем в рамках rate limits, обрабатываем пагинацию.
Как устроен пайплайн автонаполнения?
Четыре этапа. Каждый может сломаться по-своему.
-
Сбор. Парсер обходит источники по cron-расписанию. Сырые данные пишем в промежуточную таблицу — не сразу в
b_iblock_element. Логируем всё: сколько страниц обошли, сколько элементов распарсили, где получили 403 или timeout. Без логов отладка парсера — гадание на кофейной гуще. -
Нормализация. Здесь основная работа:
- Очистка HTML-тегов, лишних пробелов, Unicode-мусора
- Единицы измерения: «мм» → «мм», «millimeters» → «мм», «миллиметр» → «мм»
- Маппинг категорий поставщика → разделы инфоблока Битрикс. У одного поставщика «Ноутбуки», у другого «Ноутбуки и планшеты», у третьего «Laptops» — всё в одну секцию
- Дедупликация по артикулу, EAN/GTIN. Один товар от трёх поставщиков не должен появиться трижды
-
Загрузка в Битрикс. Через
CIBlockElement::Add()для новых элементов,CIBlockElement::Update()для существующих. Изображения: скачиваем, ресайзим черезCFile::ResizeImageGet(), конвертируем в WebP. Свойства — черезCIBlockElement::SetPropertyValuesEx(). SEO-мета через\Bitrix\Iblock\InheritedProperty\ElementValues. ЧПУ генерируем из транслитерации названия. -
Обновление. Ключевой момент — не затереть ручные правки контент-менеджера. Обновляем только цену, остатки, активность. Описание и фото, доработанные вручную, помечаем флагом
UF_MANUAL_EDITв свойствах элемента и пропускаем при импорте. Товары, пропавшие из фида — деактивируем, но не удаляем.
Почему мониторинг цен конкурентов необходим?
Отдельная подсистема со своей спецификой:
| Параметр | Как устроено |
|---|---|
| Частота | От раза в день до каждых 2 часов — зависит от волатильности рынка |
| Сопоставление | По артикулу, EAN, нечёткое сравнение названий через расстояние Левенштейна |
| Хранение | Своя таблица vendor_price_monitor с историей, не инфоблоки |
| Алерты | Telegram/email при отклонении цены конкурента более чем на X% |
| Автоправила | «Держать цену на 3% ниже минимальной среди конкурентов, но не ниже себестоимости + 15%» |
Результат — дашборд: ваш товар vs конкуренты, история цен, тренды. Менеджер видит, где можно поднять цену без потери позиции, а где нужно реагировать.
Модуль импорта CSV/XML: настройка под ваш формат
Для файлов от поставщиков — кастомный модуль с админкой:
- Настраиваемый маппинг: «колонка B в файле → свойство BRAND инфоблока»
- Автодетект кодировки (CP1251, UTF-8, UTF-16) через
mb_detect_encoding()с проверкой - Загрузка изображений по URL с очередью — чтобы не забить канал
- Инкрементальное обновление по хешу строки: изменилась строка — обновляем, нет — пропускаем
- Cron-расписание, отчёт: создано 145, обновлено 892, ошибок 3 (с деталями)
Большие файлы: CSV обрабатываем батчами по 1000 строк через fgetcsv(), XML потоково через XMLReader, фоновое выполнение через очередь агентов Битрикс — никаких PHP-таймаутов.
Правовая сторона — что важно учесть
-
robots.txt— уважаем. Crawl-delay — соблюдаем. - Частота запросов — 1–2 в секунду, не больше. Не нужно DDoS-ить чужой сайт.
- Контент производителей — используем. Уникальные авторские тексты — не копируем.
- Персональные данные — не собираем.
Что входит в разработку парсера под ключ?
| Составляющая | Описание |
|---|---|
| Прототип | Парсер 1–2 источников за 2–3 дня для оценки качества данных |
| Основной парсер | Полный сбор данных с одного источника (статический/динамический) |
| Модуль импорта в Битрикс | Нормализация, загрузка, обновление, админка маппинга |
| Мониторинг цен | Если требуется – система сбора и алертов (до 10 конкурентов) |
| Документация | Описание архитектуры, инструкция по обновлению селекторов |
| Поддержка | Гарантия 3 месяца на бесперебойную работу, правка при изменении вёрстки донора |
Как мы работаем и сроки
- Прототип — парсер для 1–2 источников за 2–3 дня. Оцениваем качество данных, подводные камни (защита Cloudflare, капча, динамическая подгрузка).
- Разработка — полный пайплайн: парсер → нормализация → импорт в Битрикс → админка для управления.
- Тестирование — прогоняем на полном объёме каталога, проверяем edge-кейсы (пустые поля, кривой HTML, битые картинки).
- Запуск — настраиваем cron, мониторинг ошибок через Telegram-бот.
- Поддержка — конкурент переделал вёрстку? Обновляем CSS-селекторы в парсере.
| Задача | Сроки |
|---|---|
| Парсер одного сайта (статический HTML) | 3–5 дней |
| Парсер SPA-сайта (Puppeteer/Playwright, обход защиты) | 1–2 недели |
| Модуль импорта CSV/XML в Битрикс | 1–2 недели |
| Система мониторинга цен (5–10 конкурентов) | 2–4 недели |
| Комплексная система автонаполнения | 4–8 недель |
| Поддержка и адаптация парсеров | по подписке |
Свяжитесь для оценки вашего проекта — мы предложим оптимальное решение под ваш бюджет. Гарантируем стабильную работу парсеров и полную поддержку в течение всего срока использования.